Pub/Sub messages to Snowflake


Pub/Sub is an asynchronous and scalable messaging service that decouples services producing messages from services processing those messages
c.f. cloud.google.com/pubsub/docs/overview
Some streaming processes rely on messages being received and provided by a message bus. It doesn't really matter if this bus is hosted by Google (Pub/Sub), Microsoft (Event Hubs), Amazon (Kinesis) or wherever, the point of this article is: There exist cases when you want to capture such messages and put them into your favorite data cloud for analysis.
One such example could be the tracking data published to such a Pub/Sub by the Snowplow Enricher: docs.snowplow.io
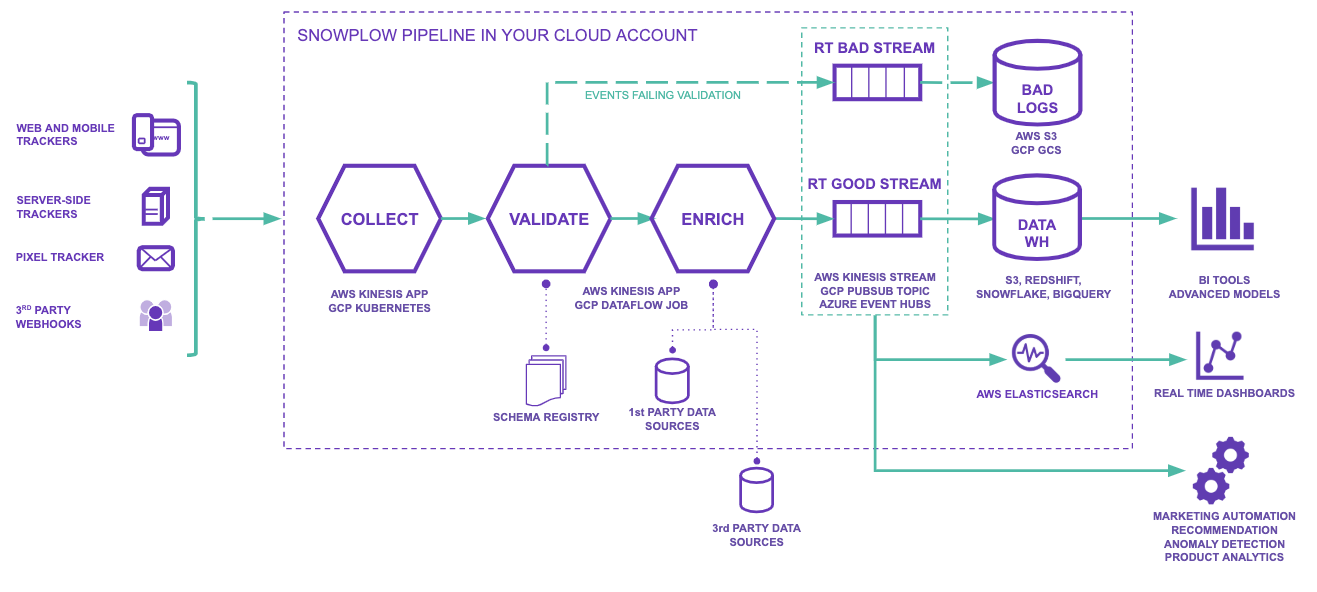
After the tracking data is enriched, it could be analyzed. However, it first must land in the DWH of choice. In this case: How do we get GCP Pub/Sub messages into Snowflake?
Snowplow offers a recommended approach, but there are a few (current and potential future) alternatives with pros and cons. To compare those, let's presume a volume of about 1kk events/messages per month tracked via Snowplow and published in Pub/Sub.
GCP Dataflow, aka Apache Beam
A Dataflow, the aforementioned recommended approach, is basically a hosted instance of Apache Beam. Pub/Sub messages get transformed (to CSVs on GCS) and can then be bulk-loaded into Snowflake via Snowpipe (or however you bulk-load stuff into Snowflake).
- Result: near-real-time or batch ingestion of data into Snowflake
- Additional requirements: the data in the message gets transformed to CSVs on GCS (aka "blobs"), but those can be loaded into a atomic Snowflake table easily (via Snowplow's RDB-Loader or any other way you'd load data from cloud storage into Snowflake - cf. next section, too)
- Cost: it's a 24/7 running Apache Beam instance. Even if we ignored the GCS cost, just the Dataflow component will be something around $80 per month.
Build your own Create-Blob-API
To create blobs from JSON, you don't really need Apache Beam - you just need an endpoint writing the JSON into your preferred data lake. Snowflake doesn't require the blob to be a CSV, it can handle JSON very well, so the transformation from one into the other is really optional.
With Azure Logic Apps (or Power Automate Premium) you create a HTTP endpoint Pub/Sub can push the message to (when pushing the message, it's data gets Base64-encoded, but again: not a big deal to decode that back in Snowflake later), respond and create a blob from the message's content:
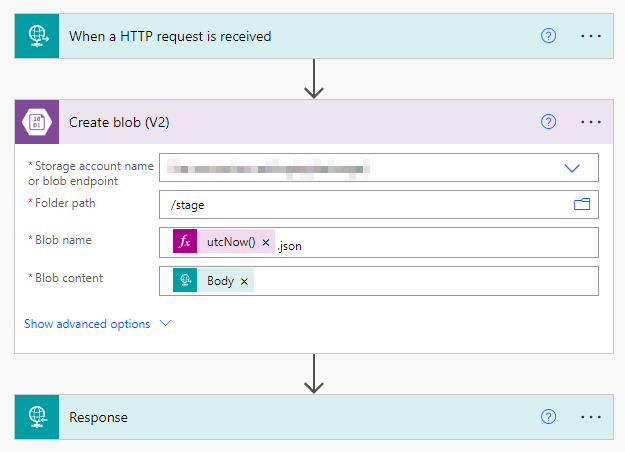
This way, you create a lot of tiny blobs (one JSON per message), in our example, about 1kk per month. Think about applying some lifecycle management on them and maybe put them into folders to keep at least some order 🤓
Side note: Event Hubs can store messages in blobs natively, so no need for an extra endpoint there. That also implies you could replace the Logic App by sending the message from Pub/Sub or Kinesis to an Event Hubs endpoint 😜
Finally, ingest the blobs into Snowflake whichever way you like, i.e. auto-ingest or bulk-load them.
- Result: near-real-time or batch ingestion of data into Snowflake
- Additional requirements: a Logic/Power Automate App and lots of blobs
- Cost: if you already have a Power Automate Premium subscription, mainly the blobs add some cost. If you require near-real-time data in Snowflake and hence auto-ingest the messages, the pricing really depends on the platform you're using, but generally I'd say it's not too expensive - a low 2-digit amount
BigQuery as temporary storage
Since Pub/Sub topics can be streamed into BigQuery directly without additional charges for the ingestion, this is currently my second-best option (the best follows later):
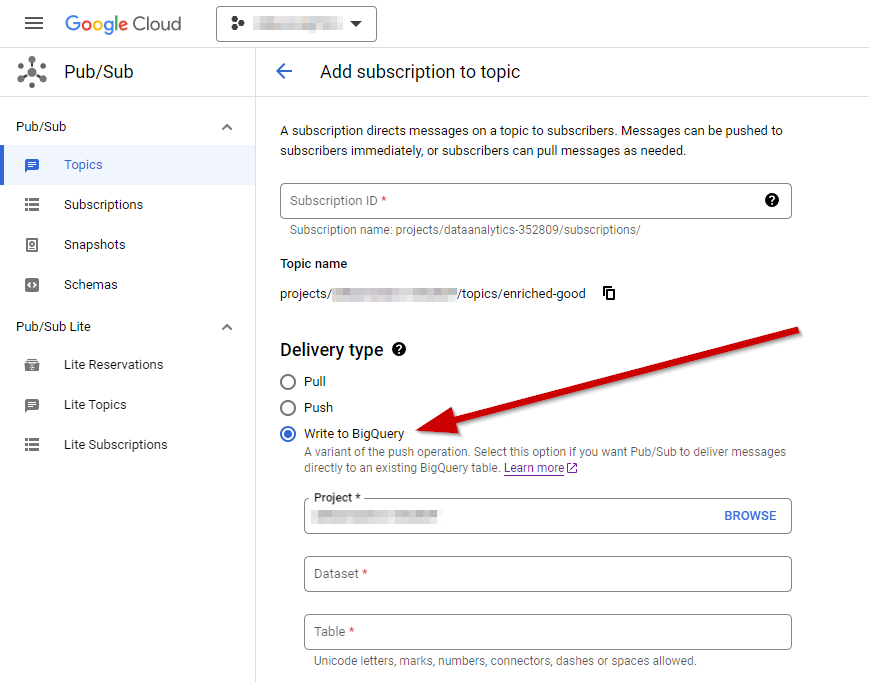
The messages stored in BigQuery contain the information we're looking for, but obviously BigQuery wasn't the final destination of the data. So we have to get the messages out of BigQuery and into Snowflake. But that job can be done with virtually any ELT/ETL tool on the market having a connector to both of the two, so I won't go into details here.
Additionally, the data is untransformed. Not a big issue, as Snowflake happily deals with semi-structured data. In our example, the message contains raw TSVs - so not even semi-structured data, but the TSVs need to be inserted into a Snowflake table at some point. I'd recommend doing this by utilizing a fitting file format with the copy into:
CREATE OR REPLACE FILE FORMAT STAGE.SNOWPLOW.FF_TSV
TYPE = 'CSV'
COMPRESSION = 'AUTO'
FIELD_DELIMITER = '\t'
RECORD_DELIMITER = '\n'
SKIP_HEADER = 1
FIELD_OPTIONALLY_ENCLOSED_BY = NONE
TRIM_SPACE = FALSE
ERROR_ON_COLUMN_COUNT_MISMATCH = TRUE
ESCAPE = '\134'
ESCAPE_UNENCLOSED_FIELD = '\134'
DATE_FORMAT = 'AUTO'
TIMESTAMP_FORMAT = 'AUTO'
NULL_IF = ('')
;- Result: copying data from BigQuery to Snowflake probably happens in batches
- Additional requirements: additional pipeline from BigQuery to Snowflake needed
- Cost: If BigQuery utilizes partitions and lifecycle management, and you don't query the messages stored there too much, it's free. The only component adding some cost is the additional pipeline
Side note: Even though you probably won't copy the data too frequently into Snowflake (as that might result in expensive pipeline runs or even charges for BigQuery because you query it too much), you can still query the temporary data in BigQuery for some near-real-time use cases, eg. debugging/monitoring whether data arrives at all or counting the current users tracked by Snowplow:
select
split(data, ' ')[offset(0)] as app_id
, count(distinct split(data, ' ')[offset(15)]) as users
from DATASET.TABLE
where publish_time >= timestamp(date_sub(current_datetime(), interval 30 minute))
group by 1
order by 2 descApache Kafka
Since Kafka can subscribe to Pub/Sub (or Event Hubs or Kinesis), you could host your own Connector somewhere and utilizing Snowpipe Streaming to push the messages into Snowflake. However, then you self-host the connector, which comes with it's own cost. Phani Raj wrote a great walkthrough for Event Hubs, but it works similarly for Pub/Sub.
- Result: near-real-time ingestion
- Additional requirements: self-managed Kafka Connector
- Cost: self-hosting obviously means you need a VM and maintain the connector
Confluent
You can achieve the same result as self-hosting your connector by letting others do the hard work. Setting up the stream in Confluent (following their onboarding how-to) takes a few minutes and you can forget about it. However, hosted Kafka isn't free 🤓
- Result: near-real-time ingestion
- Additional requirements: managed Kafka Connector by Confluent
- Cost: about $100 per stream and month (the relevant factor here are the two connectors used)
Other managed/hosted Kafka
There are a couple alternatives to Confluent and I particularly would like to mention two:
Striim has a target-connector for Pub/Sub, but no source-connector (yet). If they add one at some point in the future and 10kk free events per month, this might become an immediate candidate solution.
And then there is Decodable - who already offer a free tier and provide connectors to both Pub/Sub as a source and Snowflake as a target. Plus: With (managed) Apache Flink in the middle, transforming the TSV into a Table simply requires a SQL statement:

As long as Decodable offers this free tier, this is definitely my preferred option:
- Result: near-real-time ingestion
- Additional requirements: managed Kafka + Flink by Decodable
- Cost: since there is no cost for data ingress on Snowflake and the free tier is perfectly sufficient for my needs, this pipeline is free
Notification Integration - maybe?
Since Snowflake utilizes Notification Integrations to auto-ingest files from cloud storages, it obviously can subscribe to Pub/Sub topics. However, I didn't manage to get those messages into Snowflake (yet) if they are not related to cloud storage updates. Maybe somebody else has an idea/opinion on this? 😉
- Result: near-real-time ingestion
- Additional requirements: just a Notification Integration... probably...
- Cost: ❓
To summarize: as long as Decodable has this free tier, make good use of it! Otherwise: if batches are fine, the BigQuery approach is an almost-free and reliable option. If near-real-time is a requirement, it (as always) comes down to budget, your existing tool-stack or future feature develompent 😉